





[Text Mining]Text clustering and topic modelling
This post is based on the 732A92 Texting Mining course, given by Marco Kuhlmann at LiU in 2019.
在進入 Text clustering 前我想要先介紹 Clustering。
Clustring
-
Clustering (分群)是一種 unsupervised learning(非監督學習)
- Typical applications
- As a stand-alone tool to get insight into data distribution
- As a preprocessing step for other algorithms
- Cluster: a collection of data objects。但什麼樣的 data 會被歸在同一個 cluster 呢? 這就是 clustering 最重要的概念,Similar 和 Dissimilar。
- Similar to one another within the same cluster
- Dissimilar to the objects in other clusters
=> 而提到 Similar 和 Dissimilar 就要必須要提到 distance (or similarity) measures。有了 distance(similarity)才有辦法定義 Similar 和 Dissimilar。
Distance(Similarity)
- Distances are normally used to measure the similarity or dissimilarity between two data objects
Distances 可以有很多種定義方式,但不管怎麼定義,都一定要符合以下的 properties。
- \(d(i, j) \ge 0\) (non-negativity)
- \(d(i, i) = 0\) (identity of indiscernibles)
- \(d(i, j) = d(j, i)\) (symmetry)
- \(d(i, j) \le d(i, k) + d(k, j)\) (triangle inequality)
Minkowski distance
\(d(i, j) = \sqrt[q]{(|x_{i_1} - x_{j_1}|^q + |x_{i_2} - x_{j2}|^q + \ldots + |x_{i_p} - x_{j_p}|^q)}\) , q is a positive integer
- If q = 1, d is Manhattan distance
- If q = 2, d is Euclidean distance
Binary Variables
- symmetric binary variables: both states are equally important; 0/1
- asymmetric binary variables: one state is more important than the other (e.g. outcome of disease test); 1 is the important state, 0 the other
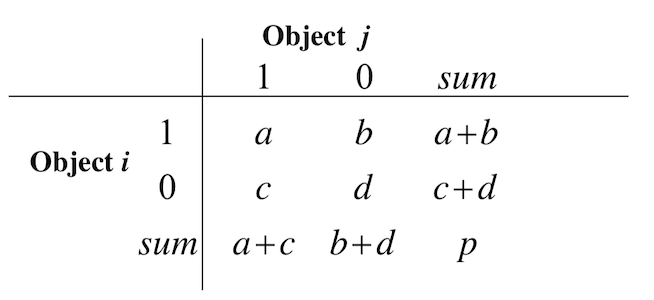
- Accuracy for symmetric binary variables
- Jaccard similarity for asymmetric binary variables
Text clustering
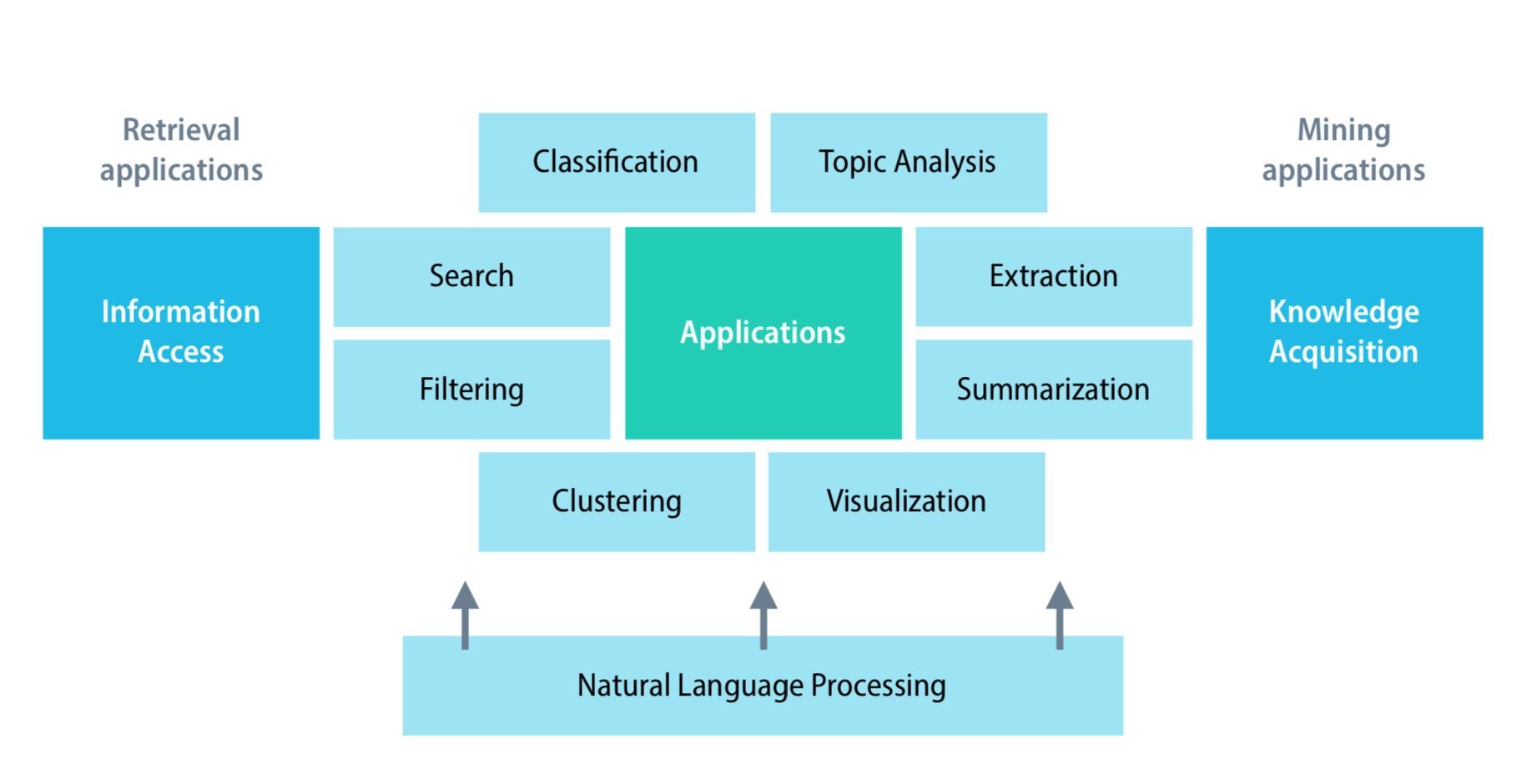
上圖是 Conceptual framework for text mining,而這篇要介紹的是 Clustering 和 Topic Analysis。
-
Text clustering is the task of grouping similar texts together. What is considered ‘similar’ depends on the application.
-
Clustering is a central tool in exploratory data analysis, where it can help us to get insights into the distribution of a data set.
-
Clustering is also useful as a pre-processing technique in knowledge-focused applications. Example: Brown clustering
Similarity measures
剛剛前面提到的 Similarity,如何用在 text 上呢?
Accuracy for symmetric binary vectors
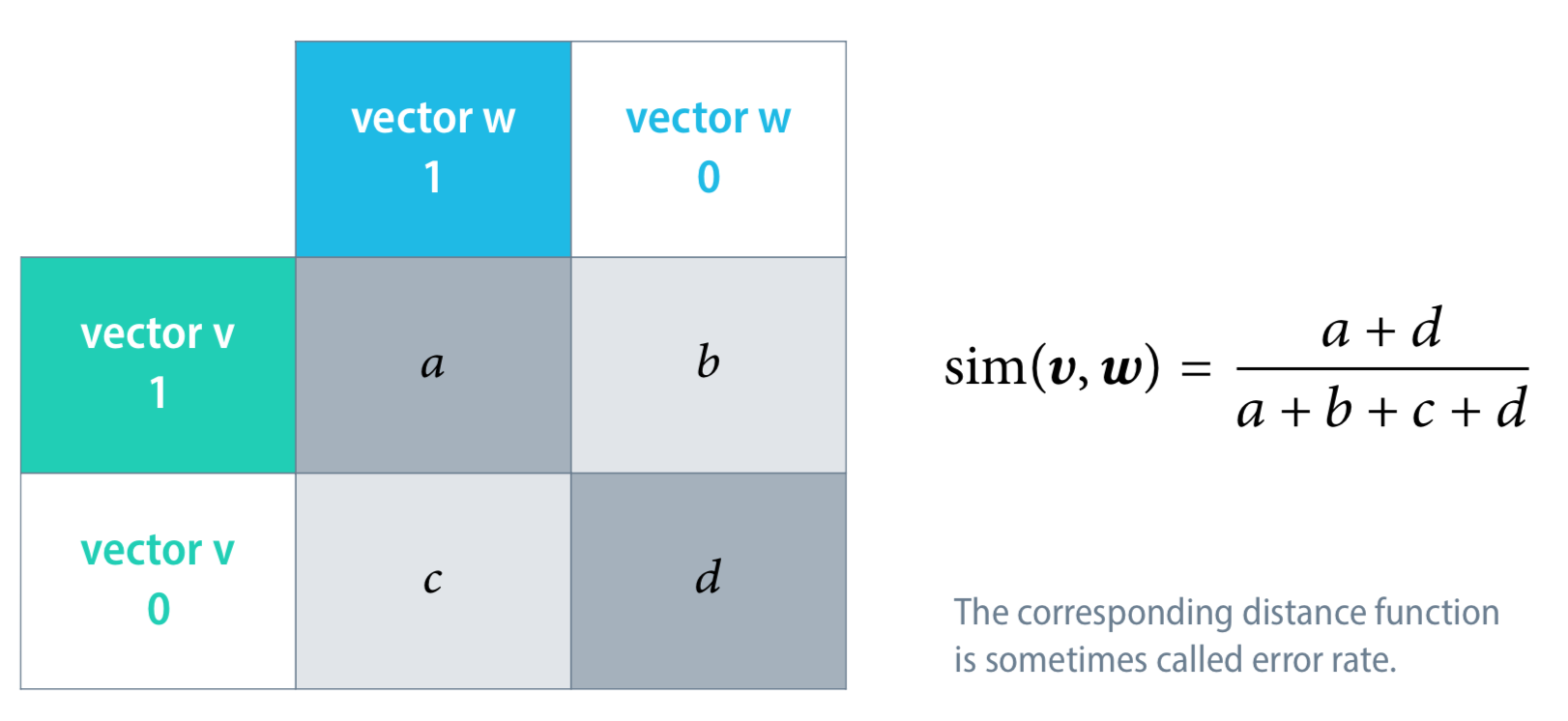
Jaccard similarity for asymmetric binary vectors
Hard clustering and soft clustering
Hard clustering
- Each document either belongs to a cluster or not. Ex. Hierarchical clustering(brown clustring), Partitioning clustering(k-means), Density-Based clustering(DBSCAN)
Soft clustering
- Each document belongs to each cluster to a certain degree. Ex. LDA (topic model)
An overview of hard clustering methods
Hierarchical clustering
This method does not require the number of clusters k as an input, but needs a termination condition
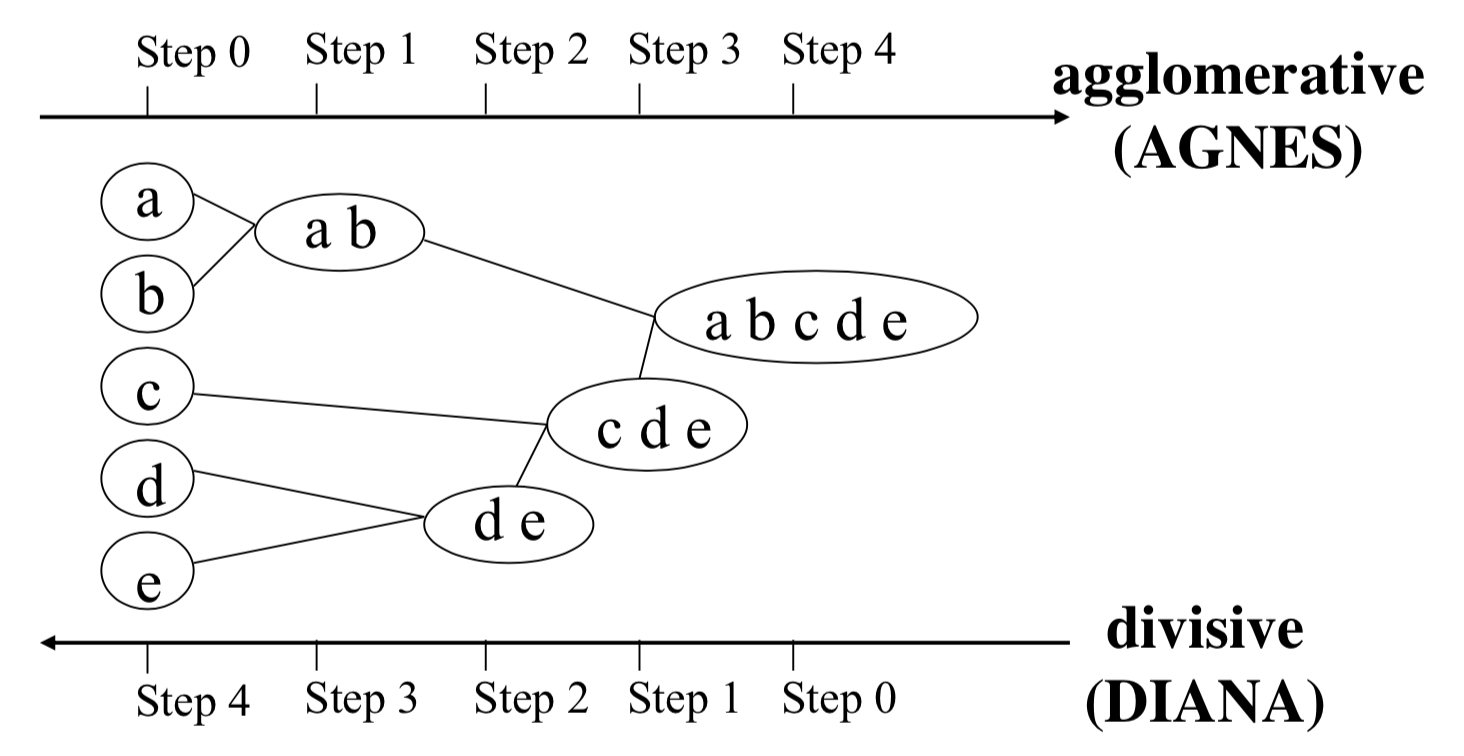
-
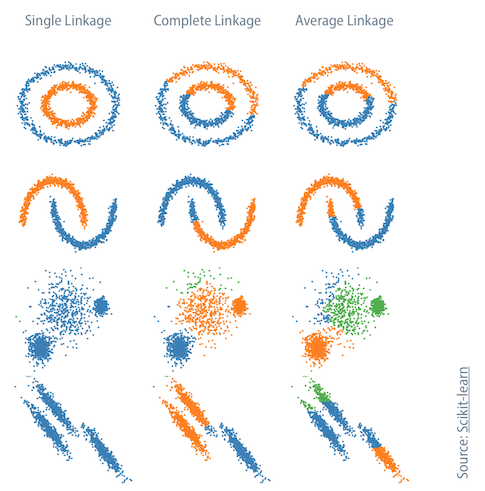
Agglomerative: Each document starts in its own cluster. Hierarchy is created by merging pairs of clusters. 將點倆倆合併,最後所有的點會全部在同一個 cluster 裡。那至於要用什麼決定要將兩個點合併呢?這時候又有 Linkage criteria 來決定,eg. Single-link, Complete-link, Average-link 等等。不同的 linkage criteria 會導致不同的分群結果,如下圖。
-
Divisive clustering: All documents start in one cluster. Hierarchy is created by splitting clusters recursively.
- Brown clustring
Partitioning clustering
-
K-means
-
Issues with the k-means algorithm
- The k-means algorithm always converges, but there is no guarantee that it finds a global optimum. (Solution: random restarts)
- The number of clusters needs to be specified in advance, or chosen based on heuristics and cross-validation. (Example: elbow method)
- The k-means algorithm is not good at handling outliers – every document will eventually belong to some cluster.
- K-means is restricted to clusters with convex shapes => Density-Based clustering
Density-Based clustering
- The basic idea behind density-based algorithms is that different regions of the vector space can be more or less densely populated.
- Under this view, clusters can take any shape; they are not constrained to convex clusters as in k-means.
Directly density-reachable
- DBSCAN
Evaluation of hard clustering
Intrinsic and extrinsic evaluation
- In intrinsic evaluation, a clustering is evaluated based on internal measures such as coherence and separation. Are documents in the same cluster similar? Are clusters well-separated?
- In extrinsic evaluation, a clustering is evaluated based on data that was not used for the clustering, such as known class labels. cluster purity, Rand index
Rand index
假設一個集合中有N篇文章 一個集合中有N(N-1)/2個集合對 TP:同一類的文章被分到同一個簇 TN:不同類的文章被分到不同簇 FP:不同類的文章被分到同一個簇 FN:同一類的文章被分到不同簇 Rand Index度量的正確的百分比 RI = (TP+TN)/(TP+FP+FN+TN)
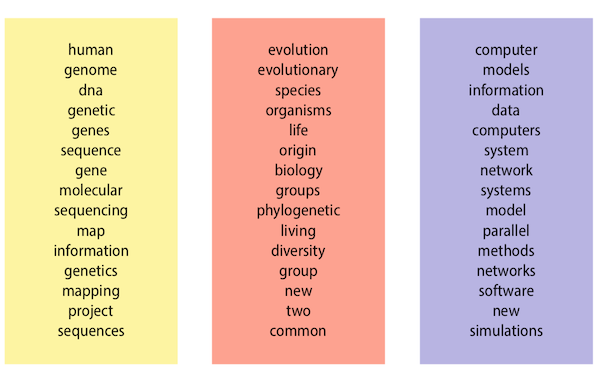
Topic models
- A topic model is a statistical model for representing the abstract topics that are expressed in a collection of documents.
- Topic models are examples of soft clustering techniques – each document belongs to each cluster (topic) to a certain degree.
Latent Dirichlet Allocation (LDA)
LDA有兩個原則,
- 每個 domcuments 是由多個 Topic 組成(each document belongs to each cluster (topic) to a certain degree)
- 每個主題會有不同的 terms 來描述,且同樣對詞可以同時出現在不同的主題。

Reference:
732A92 Texting Mining
732A75 Advanced Data Mining
自然語言處理 – Brown Clustering
直觀理解 LDA (Latent Dirichlet Allocation) 與文件主題模型
聚類評價指標 Rand Index,RI,Recall,Precision,F1