





[Machine Learning]Boosting and Adaboost
Boosting
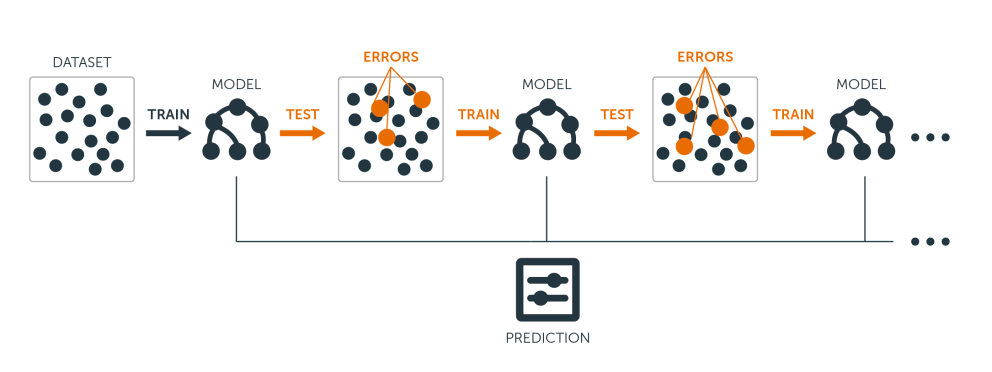
From: Introduction to Boosted Trees
Boosting 也是一種 Ensemble learning,它會結合多個弱分類器(weak classifiers)成為一個較準確的分類器,也可以應用在 regression 上。
和 Bagging 有什麼不同?
Bagging 各個 classifier 產生的過程是獨立的,但 Boosting 後產生的 classifier 與前面的 classifier 有關。也就是說,Bagging 的 classifier 可以並行產生,但 Boosting 必須要有順序的產生。所以時間上來說,Bagging 可以節省比較多的時間。
與前面的分類器有關?
在 Boosting 中,每一次產生 classifier 後,後面的 classifier 會根據前面 classifier 的結果調整每個點的權重。
在前一個 classifier 分類錯誤後,在後一個 classifier 的權重會比較重,而表現較好的則會權重減少。這就是和 Bagging 最大的不同,Bagging 中所有的點都是隨機選取,且權重都是一樣的。
簡單來說,Boosting learns features from data.
步驟
- 用最原始的 training data 跑一個 classifiers
- 利用這個 classifiers 提高分類錯誤的點的權重,降低分類正確的點的權重。
- 重複第二步驟 N 次,最後使用權重的平均值。
AdaBoost
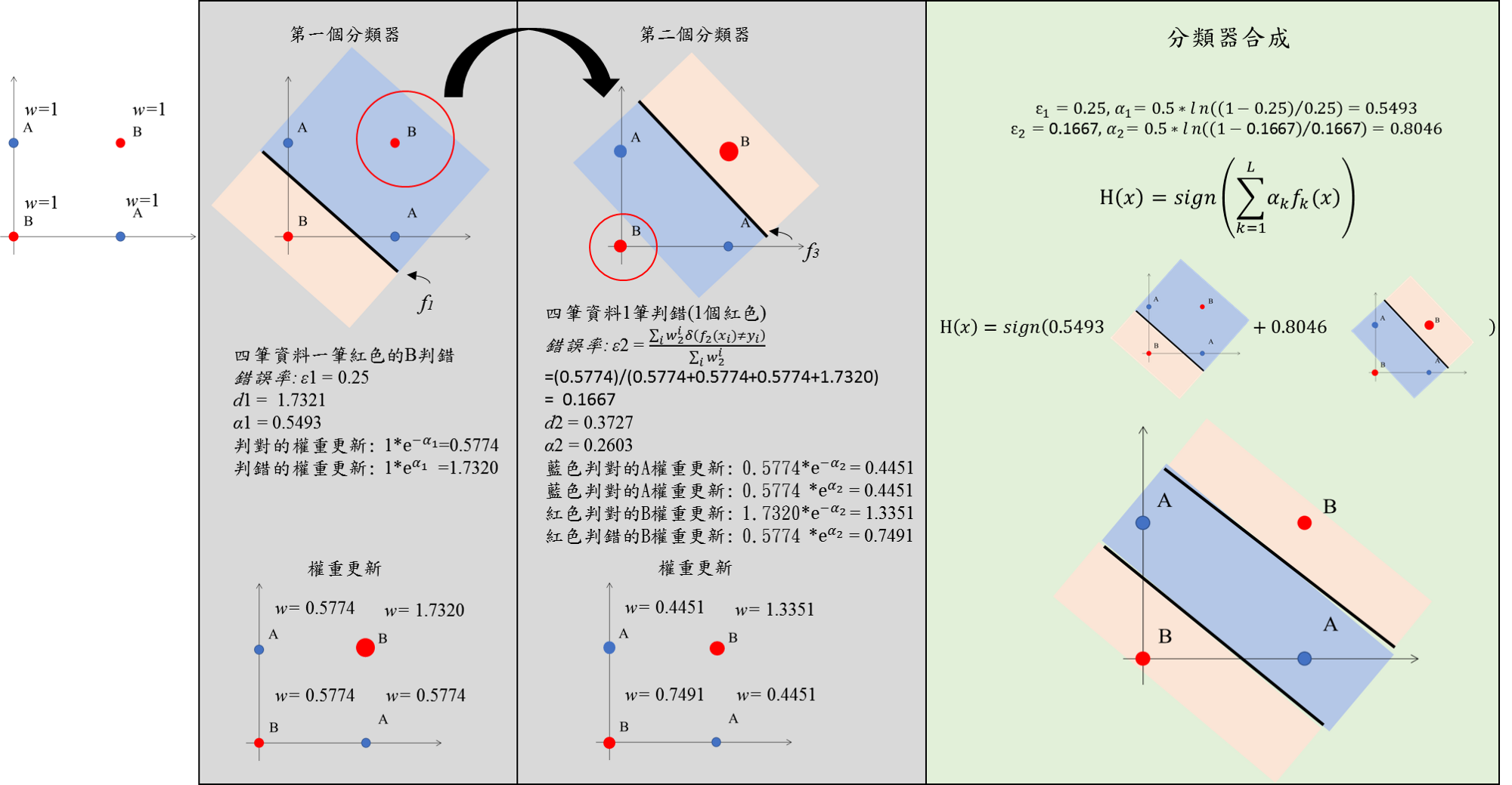
From: 機器學習: Ensemble learning之Bagging、Boosting和AdaBoost
AdaBoost 應用了 boosting 的方法。
概念
假設現在有 n 個樣本,要執行 boosting T 次。
第一次將所有樣本的權重都設為 \(\alpha_i\) = 1/n, i = 1, …, n
對所有 t = 1, …, T
- 根據樣本的權重 \(\alpha_i\) 建立出 classifier \(f_t(x)\)
- 使用 \(f_t(x)\) 後計算 \(\epsilon_t\) 誤差
- 利用 \(\epsilon_t\) 算出係數 \(w_t\)
- 再重新計算 \(\alpha_i\)
最後的 model 就會是:
\(\hat{y} = sign \sum_{t=1}^{T} w_i f_t(x)\)
AdaBoost 的優勢就是讓 model 能夠從錯中學,使用提升與降低權重的方式讓分類錯誤的點可以在下一次的 model 中被改進。
Reference:
决策树(二)
機器學習: Ensemble learning之Bagging、Boosting和AdaBoost
AdaBoost和随机森林的区别
Machine Learning - University of Washington
机器学习算法优缺点及其应用领域