





[Machine Learning]Bagging
Bagging
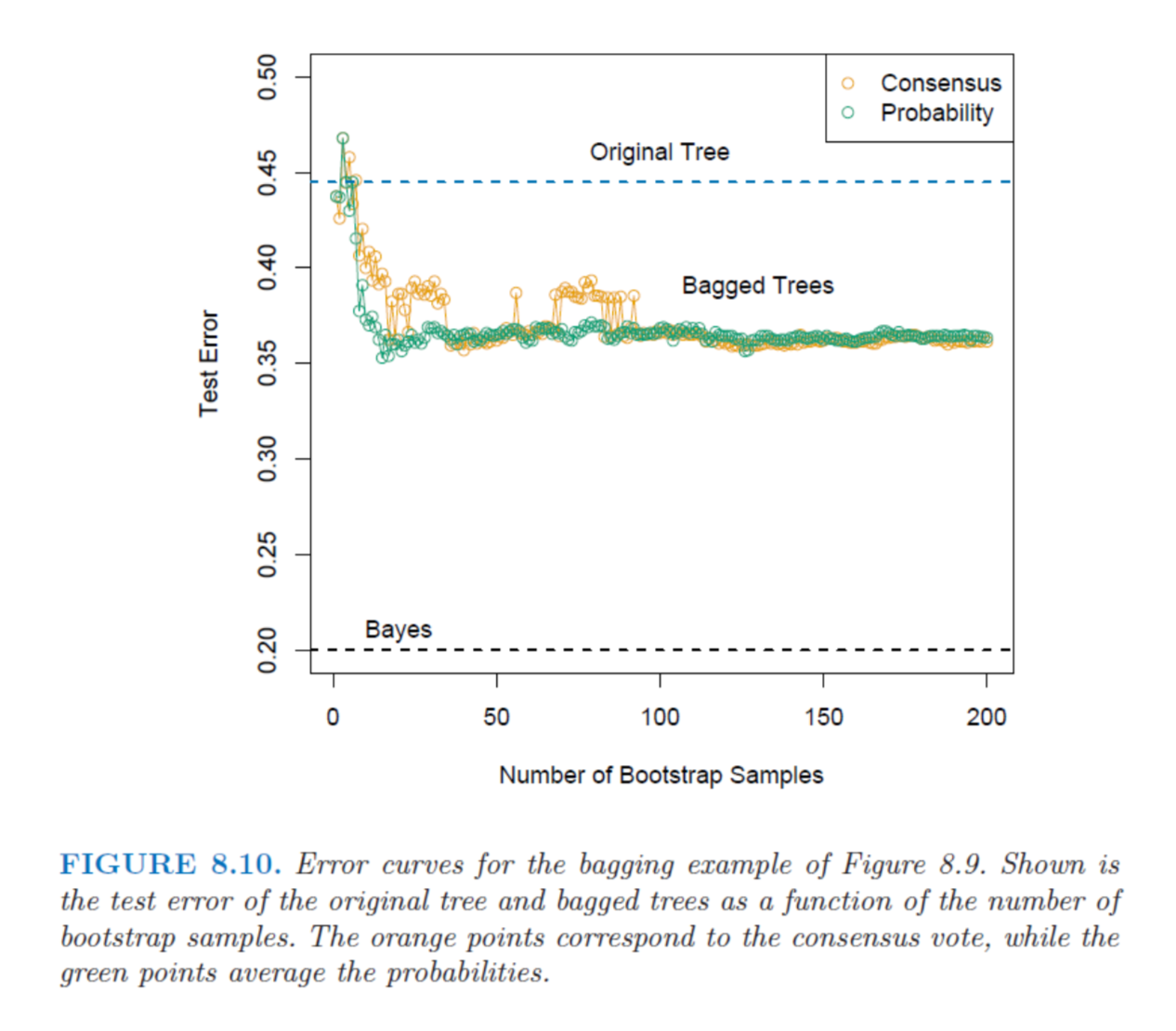
From: Hastie, T., Tibshirani, R. and Friedman, J. The Elements of Statistical Learning. Springer, 2009. p.285
Bagging 是什麼?
Bootstrap aggregating (bagging) is a machine learning ensemble meta-algorithm to improve classification and regression models in terms of stability and classification accuracy. It also reduces variance and helps to avoid ‘overfitting’. Although it is usually applied to decision tree models, it can be used with any type of model. (Decision Tree - Bagging)
簡單來說,Bagging是一種 Ensemble learning方法,它集結一些 model 來做最後的決策。通常會是集結表現沒那麼好的 model,讓這些 model 一起做決定,一種三個臭皮匠勝過一個諸葛亮的感覺。
Decision tree 是一個常見的 weak classifier,所以如果在 decision tree 上使用 bagging,可以讓最後表現結果比較好,也避免 overfitting 的情況。
Boostrap
在開始說明 bagging 步驟前先介紹 bootstrap。
bootstrap 是一種抽樣方法。假設今天有一組資料,裡頭共有 N 個樣本,我們想要有 m 個大小為 N 的樣本作為訓練資料。方法是,每次從這 N 個樣本隨機抽取,且每次都是取後放回(也就是有些樣本可能被抽到一次以上,有些樣本可能沒被抽到),同樣的方法重複 m 次,這樣我們就會有 m 組樣本數為 N 的 y 資料集。
這樣的方法在樣本數量少時很有用。如果樣本小,但我們用 train-validation-test 這樣的方式訓練資料,訓練的樣本資料非常小,會造成 bias 較大的問題。而使用 bootstrap 不會減少樣本的數量,也能保留 test data。
如何操作?
- 使用 boostrap 方法從 training data 中採集 B 組樣本數與 training data 相同的資料集。
- 這 B 組資料集都建立一個 model, \(f_b(x)\),共產生 B 個 model。
- 最後預測的結果就是將這 B 個 model 做統合。在分類問題上,可以平均各個 model 的 posterior class probabilities,或是使用 majority voting。(選機率比較大的結果或是多數決);在回歸上,則取平均值。
從最上圖可以看到,不論是使用機率或是投票決定,bagging 選出的結果的 test error 都要比個別的 model 表現較好。
除了 Bagging 外,Ensemble learning 還有另一種常見的方法 Boosting,這篇先到這裡之後繼續介紹。
Reference:
機器學習: Ensemble learning之Bagging、Boosting和AdaBoost
随机森林(Random Forest)算法原理
The Elements of Statistical Learning
Pattern Recognition and Machine Learning